
처음에 Java Spring 프로젝트를 다룰 때 모듈화에 대해 어렴풋이 알고는 있었다. 다만, 당시에는 생소한 개념이었고 이해하기 어려웠었다. 프로젝트를 만들 때 멀티모듈을 어떻게 만들어야 하는지부터 Github나 블로그 등을 엄청 찾아다녔다. 우아한형제들의 블로그에서도 멀티모듈에 대한 설계 게시글이 있어서 어떻게 의존성의 범위를 설정하고 프로젝트 설계를 했는지 구체적으로 설명이 되어 있는 게시글도 찾아보고 그랬지만, 처음부터 잘 모르는 상태에서 이를 실천하다간 나중에 어려워 질것 같아서 단일 모듈로 시작했었다.
프로젝트를 만들어서 실제 서비스에 적용하고 팀원들이 Java Spring 프로젝트들을 하나씩 만들다 보니 저장소도 늘어나기 시작했는데 설정이나 Entity, 클라이언트 등 중복되는 클래스들이 계속 생기게 되었다.
처음엔 maven 라이브러리로 빼놓는 것을 생각하고 진행해봤다. 각 프로젝트에서 사내에서 관리되고 있는 중복 코드를 따로 저장소에서 관리하고 버전별로 배포하여 각 애플리케이션에서 의존성을 버전으로 가져오면 관리가 쉬울 것 같다고 판단했기 때문이다. 클라이언트 부분만 라이브러리로 빼내어 maven 라이브러리로 만들어서 사용해봤는데 라이브러리 수정, 배포, 애플리케이션별 수정, 다시 배포... 등 생각보다 많이 번거로워서 결국 이 방식은 지양하게 되었다.
결국 maven 라이브러리로 관리하는 것보단 직접 프로젝트에서 모듈로 나누어 관리하는 방식을 적극적으로 택하게 되었다.
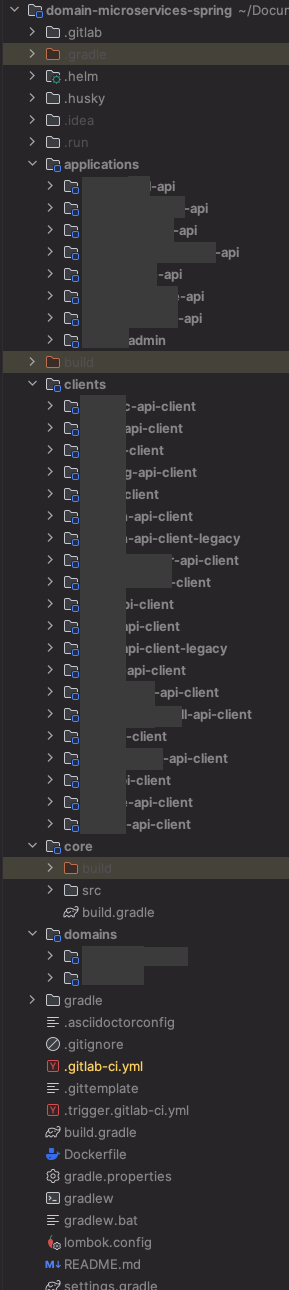
팀의 상황에 따라 모듈은 크게 네 가지로 나누어 의존성을 관리하게 되었다. 애플리케이션, 타 API를 호출하는 클라이언트, 공통으로 사용되는 Entity나 Repository 등이 담긴 도메인, config나 예외 처리 같은 공통적인 요소가 있는 코어로 4가지로 분류했다. 그리고 모듈별로 품는 의존성은 아래와 같이 설정하게 되었다.
- 애플리케이션 - 클라이언트, 도메인, 코어
- 클라이언트 - 코어
- 도메인 - 코어
- 코어 - X
애플리케이션에서는 모든 요소들을 다 다루고 있기 때문에 모든 모듈을 포함하도록 했고, 각 애플리케이션에서 설정같이 공통적으로 쓰이는 부분들은 코어로 두었다. 이때 코어에서는 다른 모듈에서 공통 의존성을 가져다가 사용할 수 있도록 gradle 에서는 api 로 두었다.
도메인의 경우 정말 많은 의견이 오고 갔는데, 사내에서는 Oracle과 MySQL을 사용하긴 하지만 Oracle을 대부분 많이 사용하고 있었고 의존을 많이 하고 있다 보니 처음에는 팀에서 우선은 Entity라도 많이 만들어두자는 의견이 형성되어 일단 모든 Entity를 하나의 모듈에 넣는 것으로 시작하게 되었다. 하지만 이렇게 되다 보니 결국 나중에 각 애플리케이션에서 비즈니스 로직을 넣을 때 해당 모듈의 도메인에 넣기가 상당히 애매해졌다.
우아한형제들 블로그에 있던 것처럼 도메인은 하나의 도메인 이상을 품을 수 있되 하나의 도메인은 하나의 인프라스트럭쳐까지만 이용할 수 있다는 것을 떠올려서 한번 각 비즈니스 로직을 도메인별로 쪼개보자는 의견으로 좁혀졌다. 그러나, 사실상 각 애플리케이션에서 동일한 인프라스트럭쳐인 Oracle을 바라보고 있었고 중복되는 Entity가 계속 생기는 것은 피하는 것이 맞을 것 같아서 우선은 공통 Entity를 해당 모듈로 두기로 했다. 다만, 각 애플리케이션 별로 비즈니스 로직을 담을 경우엔 각 애플리케이션에서 해당 Entity를 상속받아 애플리케이션 모듈에서 우선 관리하도록 하고 나중에 이 부분을 모듈로 빼자는 식으로 결정되었다.
이 경우, 부모 Entity에 @DiscriminatorFormula 와 @DiscriminatorValue 를 두어 필드들을 protected 로 둔 다음, 각 애플리케이션에서 부모 Entity 를 상속한 자식 Entity 를 만들어 @DiscriminatorValue 를 쓰게 되었다. @DiscriminatorFormula 로 컬럼이 아닌 쿼리에서 Entity 를 구분하도록 하고, @DiscriminatorValue 를 통해 부모 Entity, 자식 Entity 를 구분하는 식으로 구현하게 되었다. 비즈니스 로직을 담을 때에는 자식 Entity 에 인터페이스를 추가하여 사용할 수 있도록 정해졌다. QueryDsl 으로 특정 비즈니스 로직에 대한 질의문을 작성할 때에는 애플리케이션에다가 두고, 부모 Entity 한정으로 Repository 로 공통적으로 쓸 수 있는 부분들은 도메인 모듈에 두도록 했다.
// 부모 Entity
@Entity
@Table(name = "SOME_TABLE", schema = "SOME_SCHEMA")
@SequenceGenerator(name = "SOME_TABLE_SEQ_GENERATOR", sequenceName = "SOME_FIELD_SEQ", allocationSize = 1, schema = "SOME_SCHEMA")
@Getter
@SuperBuilder(toBuilder = true)
@DynamicInsert @DynamicUpdate
@NoArgsConstructor @AllArgsConstructor
@DiscriminatorFormula("0")
@DiscriminatorValue("0")
public class SomeEntity {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "SOME_TABLE_SEQ_GENERATOR")
@Column(name = "SEQNO")
protected Long id;
@Setter
@Convert(converter = SomeStatusConverter.class)
@Column(name = "STATUS")
protected SomeStatus status;
...
}// 자식 Entity
@Entity
@SuperBuilder
@NoArgsConstructor
@DiscriminatorValue("00")
public final class BusinessSomeEntity extends SomeEntity implements ChangableBusinessSomeEntity {
@Override
public void update(SomeStatus status) {
...
}
...
}
이렇게 하면서 각 프로젝트에 생기는 공통적인 모듈은 GIT 서브트리로 관리하게 되었다. 클라이언트, 도메인, 코어에 대한 저장소를 만들고, 똑같은 모듈 구조의 여러 애플리케이션 저장소에서 각 모듈을 서브트리로 관리하는 식으로 두었다. 서브모듈보단 서브트리로 관리하게 되었는데 그 이유 중 대표적인 이유는 개발 작업을 빠르게 하기 위함이었다. 서브모듈은 각 저장소에 해시로 남기고 병합 등에서 복잡한 부분이 있는데 서브트리는 서브트리의 파일 및 변경사항도 해당 저장소에 기록되고 병합도 쉬워서 이를 고려한 결정이었다.
하지만 계속 이렇게 관리하다 보니 불편하거나 문제점이 생기게 되었다.
- 항상 각 애플리케이션 프로젝트마다 동기화 작업을 해주어야 했다. 각 애플리케이션 저장소에서 서브트리 저장소로 동기화를 해주고, 그 다음에 각 애플리케이션 저장소마다 해당 서브트리의 master를 가져와서 최신 버전으로 갱신해주어야 했다. 즉, 갱신 작업을 적어도 2번 이상을 해야 했다. 각 애플리케이션의 서브트리 파일에서 생성하거나 수정한 변경사항을 취합하는 것도 번거로웠다. 이 작업이 계속 반복되다 보니 정말 중노동이 따로 없었다.
- 의외로 서브트리에 버그가 있었다. 똑같은 방법과 순서로 진행함에도 불구하고 각 팀원들의 컴퓨터마다 다르게 작동하는 현상이 있었다.
- 각 사용자의 이해와 사용 방법에 따라 기록이 꼬아지는 경우나 기록이 날라가는 경우가 생겼었다. 또한 GIT 그래프의 경우 depth 가 상당히 많이 생기게 되는 문제도 발생하게 되었다.

결국 모듈 관리 방식을 변경하는 것을 고려할 수 밖에 없었다. 따라서 하나의 저장소 안에서 모듈화를 하고 여러 애플리케이션을 배포할 수 있는 모노레포 방식의 도입을 고려하게 되었다. 이 방식을 도입하면 적어도 아래의 문제를 해결할 수 있었다.
- 모듈화를 통해 관리하므로 중복 코드를 줄일 수 있었다. 특히, 각 저장소마다 공통 코드를 관리하기 위해 반복으로 작업하던 것을 줄일 수 있었다.
- 커밋을 보다 더 관리하기 편해진다.
- 코드리뷰를 진행할 때 하나의 MR을 통해 진행할 수 있다.
- 바운더리 및 의존성 관리가 더 편해진다.
GitLab CI/CD 파이프라인의 경우, 각 팀에서 수정하여 사용할 수도 있었지만 가능하면 SE분들이 관리할 수 있도록 두고 있었다. 사내에서는 Jenkins 등을 두고 있지 않고 모든 것을 GitLab을 통해 관리하고 있었는데 기존 방식들은 전부 단일 레포 단위의 단일 애플리케이션 배포 방식만 이루어 지고 있었다.
이를 해결하기 위해 GitLab CI/CD 파이프라인 관련해서 문서를 찾다가 Parent-Child Pipeline 방식이 있다는 것을 발견했다. 이 방식은 간단히 말하자면 Upstream과 Downstream으로 나누어 Upstream에서 Downstream을 실행하도록 하는 방식인데 부모 파이프라인에서 변경감지를 통해 어떤 모듈에서 변경사항이 일어났는지 판단하고, 자식 파이프라인에서 기존의 CI/CD 로직을 실행하도록 trigger로 만들어 줄 수 있었다.
도메인, 클라이언트, 코어와 같이 여러 곳에서 공통적으로 쓰이는 모듈은 develop, master Merge 할 때 트리거되도록 했다. 그 이유는 빌드 시간 감소를 위해 MR을 올렸을 때는 보다 빠르게 CI/CD 진행되도록 하기 위해서였다(원래는 MR할 때도 변경사항을 감지하도록 했으나 팀원들과 논의한 끝에 MR에서는 진행되지 않도록 결정되었다).
stages:
- trigger
trigger-some-api:
stage: trigger
variables:
MODULE_NAME: "some-api"
rules:
# 새 브랜치 또는 태그를 만들면 무조건 changes 가 true 로 인식하게 되어 feature/fix/hotfix 는 MR 을 생성했을 경우만 작동하도록 함
- if: '($CI_PIPELINE_SOURCE == "merge_request_event" && $CI_MERGE_REQUEST_TARGET_BRANCH_NAME != "master")'
when: on_success
changes:
- "applications/some-api/**/*"
- if: '($CI_COMMIT_BRANCH =~ /^develop|master$/) || $MODULE_NAME =~ $CI_COMMIT_TAG'
when: on_success
changes:
- "applications/some-api/**/*"
- "domains/**/*"
- "clients/**/*"
- "core/**/*"
trigger:
include:
- local: .trigger.gitlab-ci.yml
strategy: depend특히, GitLab 에서 특정 기능의 추가나 수정, 배포를 위해 새 브랜치 또는 태그를 만들면 항상 변경감지가 true 로 인식되는 문제가 있었다. 이것 때문에 모든 애플리케이션이 trigger로 Downstream이 만들어지는 경우가 생기게 되었는데, 브랜치가 추가되거나 없어지는 경우는 MR을 통해서만 작동되도록 했고 태그로는 실서버 배포시에만 사용되어 태그에 직접 애플리케이션 이름까지 적어서 배포하도록 조치했다.
rules:
- if: '$CI_PIPELINE_SOURCE == "parent_pipeline" && $CI_MERGE_REQUEST_SOURCE_BRANCH_NAME =~ /^(feature|fix|hotfix)[\-\/][a-zA-Z0-9\-]+$/'gradle-build-prod:
extends: .gradle-build
script:
- ./gradlew clean :applications:${MODULE_NAME}:build -x test -x printCoverage
rules:
- if: '$CI_COMMIT_TAG =~ /^[\w-]+-v(\d+).(\d+).(\d+)$/'
...
MR을 생성하게 되면 커밋 내 변경사항에 따라 파이프라인이 생기게 된다. MR을 통해서는 별개로 파이프라인이 생성되고 아래 그림에서 merge request 라고 뱃지가 달린 곳에서는 Upstream, Downstream이 나뉘게 된다.

develop 이나 master 의 경우 하나의 파이프라인에서 Upstream, Downstream이 나뉜다.
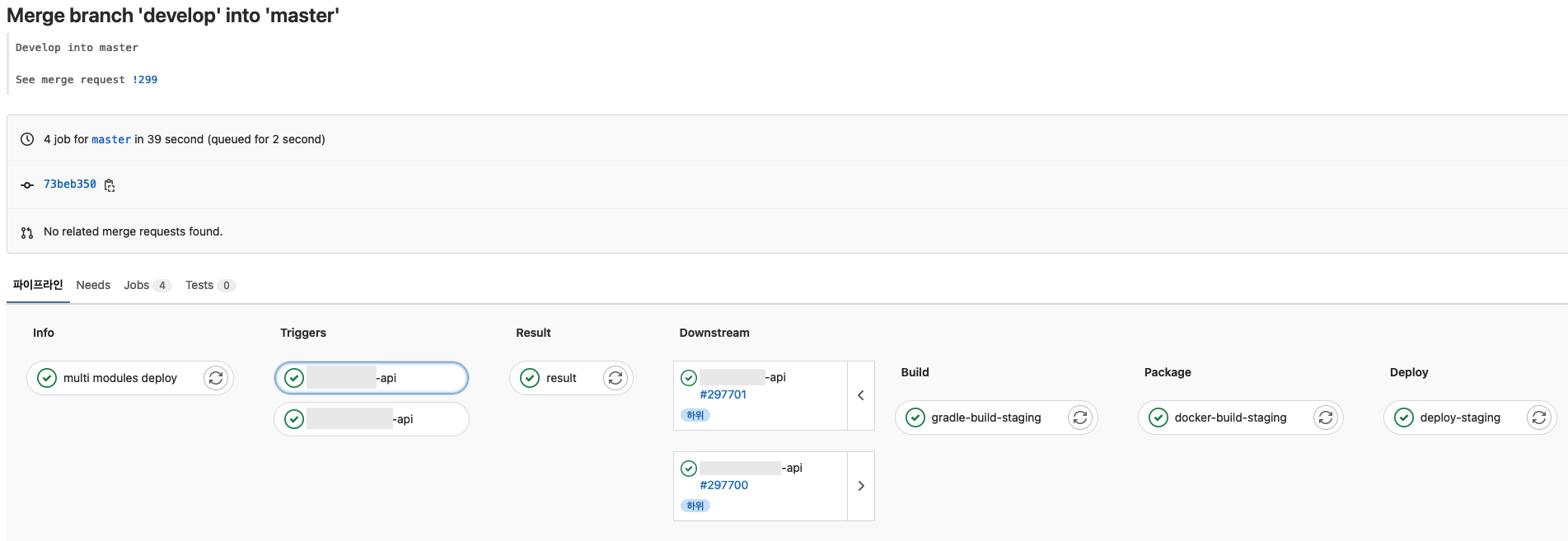
이렇게 변경함으로써 모듈 관리가 더 편해졌지만 좋은 것만 생긴 것은 아니었다. 테스트 및 빌드가 동시에 진행되면서 GitLab Runner의 리소스가 부족해지게 되고 이로 인해 빌드가 실패되는 경우가 많아졌고 동시에 시간도 오래 걸리는 문제가 발생했다. 이 문제는 인프라 문제라 SE들도 알고 있는 사항이고 바로 해결되기엔 어려운 문제라 우선은 지켜봐야 할 것으로 보인다.
'회고' 카테고리의 다른 글
| [회고] 2023년 (0) | 2024.01.01 |
|---|---|
| [회고] Graylog 에서 ELK 까지의 작업 후기 (0) | 2023.02.05 |
| [회고] 2022년 (0) | 2023.01.01 |
| [회고] 2021년 (0) | 2022.03.27 |
| [회고] SVN에서 GIT으로 이전 후 코드 리뷰 도입을 돌이켜보며 (0) | 2022.03.27 |