
사내에 로그가 남겨지고 있는 서비스들이 대부분 파일로 관리되고 있는 것이 많았는데 그 중에서 많은 트래픽이 오는 두 개의 서비스 로그 지표를 확인해보고 싶었다.
기존에는 정작 애플리케이션 단위에서 얼마나 요청이 들어오고 나가는지, 어떤 데이터가 얼마나 들어오는지를 개발팀에서 알 수 있는 방법이 없어 실제로 장애 상황이 일어났을 때도 연관 데이터를 쉽게 분석하기 어려웠다.
또한, 로그가 파일로 남겨지고 있어서 SE 분들이 로그를 삭제해도 되는지에 대한 문의가 우리팀에게 간헐적으로 전달되었고, 우리가 직접 서버로 들어가서 삭제하거나 SE 분들이 삭제하곤 했다. 이런 이슈를 이번에 따로 개선해보고 싶었다.
팀에서 해당 서비스의 로그는 오랫동안 보관하기에는 중요하지 않은 로그라고 판단했고, 주기는 1~3개월 정도 보관하기를 원했다. 그리고 우리가 따로 개발하지 않더라도 웹에서 쉽게 접근할 수 있고, 쉽게 데이터를 쌓을 수 있어야 했다. 예전에 팀내 스터디용으로 클라우드팀으로부터 대여받은 서버가 있었는데 직접 여러 도구를 이용해보다가 ELK 와 Graylog 두 가지를 후보로 올려놓게 되었다.
Graylog
ELK 의 경우 이미 다른 팀에서 똑같은 고민으로 인프라팀에게 ELK 구축 요청을 한 팀이 있었는데 인프라팀으로부터 현재 서버를 올려놓을 수 있는 공간이 없다고(사내에서 클라우드 서비스를 직접 제공하고 운영하고 있다보니 경영진에서는 AWS 와 같은 퍼블릭 클라우드 서비스보단 직접 구축해서 운영하기를 원했다) 거절당했었다. 우리가 요청을 해도 똑같은 말을 들을 가능성이 매우 컸기 때문에 ELK 보단 어쩔 수 없이 Graylog 를 바라보게 되었고, 다행히도 Graylog 는 이미 사내에서 운영중이어서 이를 선택하게 되었다.
다음으로는 로그 데이터를 어떻게 전달할까 생각하다가 GELF(Graylog Extended Log Format) 형태로 데이터를 Kafka 를 이용하여 보내는 것으로 정했다. 우리가 데이터 포멧을 정하기 보다는 Graylog에서 지원하는 포맷으로 형식을 관리하는 것이 좋아보였고, JSON 으로 보낼 것이므로 나중에 Graylog 에서 다른 스택(ex. ELK)으로 변경하게 되더라도 Kafka Topic 을 Input 으로 잡아서 필터로 사용하면 되므로 Input 을 GELF Kafka 로 선택하여 진행했다.
참고로 GELF Payload 는 아래와 같은데, 주요 특징으로는 몇 가지 고정적인 Key 들이 정해져 있고 사용자가 따로 관리하기 원하는 Key 는 이름 앞에 _ 문자를 prefix 로서 사용하게 된다. Key 중에 timestamp 가 있는데 이것은 Graylog 에서의 로그 시간으로 이용된다.
{
"version": "1.1",
"host": "example.org",
"short_message": "A short message that helps you identify what is going on",
"full_message": "Backtrace here\n\nmore stuff",
"timestamp": 1385053862.3072,
"level": 1,
"_user_id": 9001,
"_some_info": "foo",
"_some_env_var": "bar"
}Graylog 는 대시보드를 지원해주고 있는데 단순 Metric, 그래프, 테이블, 파이 차트 등 여러 표현 수단을 제공해주고 있고 Tab 별로 대시보드를 여러 개로 관리할 수 있다.

Graylog 를 사용하면서 몇 가지 불편했던 점이 있었다.
- 하나의 대시보드 내에서 여러 탭을 구성하고, 각 탭에서 고정된 데이터 기간을 설정한 위젯이 많을 경우 시간이 오래 걸리는 현상이 있었다. 각 탭에서 설정한 데이터들을 모두 가져오게 되면서 오래 걸리는 것으로 보였는데, 이 부분은 탭을 여러 개로 설정하기보단 대시보드 자체를 여러 개로 만들어서 관리하는 것이 좋아보였다.
- 아쉬운 부분으로 그래프 출력 시 x 축에 대한 간격을 설정하는 것이 불가능했다. 그래프 기간에 따라 x축 간격이 제멋대로 나오고, 이를 임의로 설정하는 부분이 존재하지 않았다.
ELK
SE분들이 있는 인프라팀에서 Kubernetes 구축을 하고 조금 시간이 지나 ELK를 엄청난 사양(상당한 TB단위의 용량과 300gb 수준의 메모리)으로 구축하면서 통합 로그 서버를 운영하게 되었다. 이때 다른 팀에서 Kibana 네임스페이스를 만들고 적극적으로 이용하는 모습을 보며 예전에 내가 데이터를 쌓게 해놓은 Graylog 데이터를 떠올렸다. Graylog 는 인프라팀에서 관리하지 않았고, 해당 Graylog 를 관리했던 담당자가 퇴사함으로써 앞으로 누가 관리할지 주체가 명확하지 않았기에 이참에 인프라팀에서 구축한 ELK 로 변경하고 싶었다. 이를 통해 전사 누구나 데이터를 같이 공유할 수 있고, 인프라팀에서도 전사 로그를 관리하기 쉬울 것으로 판단하였다.
옮기는 것은 간단했다. Kibana 네임스페이스와 인덱스 이름은 팀 내에서 같이 의견을 나누어 정해서 만들면 되었고, 데이터는 이전에 로그를 Kafka 를 통해 전달하고 있었기 때문에 Logstash 에서 input 을 kafka 로 두고 filter 에서 json 으로 읽게 해두면 되었다.
한 가지 설정이 있었다면 Key 이름 맨 앞의 _ 문자를 없애서 관리하고 싶었다. 위에서 말했듯이 GELF 에서 _ 로 prefix 를 갖는 것들은 사용자가 수동으로 추가한 것들을 의미한다.
즉, 아래의 데이터에서
{
"version": "1.1",
"host": "example.org",
"short_message": "A short message that helps you identify what is going on",
"full_message": "Backtrace here\n\nmore stuff",
"timestamp": 1385053862.3072,
"level": 1,
"_user_id": 9001,
"_some_info": "foo",
"_some_env_var": "bar"
}아래처럼 key 를 관리하고 싶었던 것이다.
{
"version": "1.1",
"host": "example.org",
"short_message": "A short message that helps you identify what is going on",
"full_message": "Backtrace here\n\nmore stuff",
"timestamp": 1385053862.3072,
"level": 1,
"user_id": 9001,
"some_info": "foo",
"some_env_var": "bar"
}사실, ELK 로 넘어감으로써 이제는 딱히 GELF 형태를 엄격하게 지키지 않아도 되었기 때문에 애플리케이션에서 직접 데이터를 남기는 부분을 바꾸면 되었다.
그래도 우선은 GELF 형식을 그대로 사용해보려고 이에 대해 찾아본 결과 Logstash 설정 파일에서 ruby 코드로 직접 입력하면 key 이름 앞의 _ 문자를 없앨 수 있는 것을 알아냈다. 말 그대로 앞에 _ 가 있을 경우 해당 key 를 지우고 다시 만드는 방법으로 진행했다.
input {
...
}
filter {
...
ruby {
code => "event.to_hash.keys.each do |key| next unless key[0,1] == '_'; if key == '_' then event.remove(key); next; end; event.set(key[1..-1], event.remove(key)) end"
}
...
}
output {
...
}그렇게 해서 아래와 비슷하게 Logstash 설정을 하게 되었고, 인프라팀에 요청해서 설정의 적용을 부탁하였다.
input
{
kafka
{
bootstrap_servers => "kafka1:9092,kafka2:9092,kafka3:9092"
group_id => "someteam-someservice"
topics => "log.api.someservice"
consumer_threads => 3
enable_metric => "false"
auto_offset_reset => "earliest"
tags => ["some-service", "some-steam"]
}
}
filter
{
if "some-steam" in [tags] {
mutate {
add_field => {
"[@metadata][elasticsearch_index_prefix]" => "some-steam"
"[@metadata][elasticsearch_index_date]" => "%{+YYYY.MM.dd}"
"[@metadata][log_file_path]" => "%{[@metadata][elasticsearch_index_prefix]}/default.log"
}
}
}
}
filter
{
if "some-service" in [tags] {
json
{
source => "message"
}
date {
match => ["timestamp", "yyyy-MM-dd'T'HH:mm:ss.SSS'Z'"]
timezone => "Asia/Seoul"
locale => "ko"
target => "timestamp"
}
mutate
{
add_field => {
"service" => "some-service"
}
}
ruby {
code => "event.to_hash.keys.each do |key| next unless key[0,1] == '_'; if key == '_' then event.remove(key); next; end; event.set(key[1..-1], event.remove(key)) end"
}
}
mutate
{
add_field => {
"[@metadata][_idx]" => "%{[@metadata][elasticsearch_index_prefix]}_%{service}_%{[@metadata][elasticsearch_index_date]}"
}
}
}
output
{
elasticsearch
{
index => "%{[@metadata][_idx]}"
}
}
인덱스를 설정할 때 timestamp 는 로그 데이터 내 GELF 포맷 형식의 timestamp 가 아니라 ElasticSearch 에 로그를 쌓을 때 생성되는 @timestamp 를 이용하기로 하였다. 이에 대해 미리 팀과 의견을 나누었는데 로그 데이터 생성과 ElasticSearch 에 로그가 적재되는 시점과 크게 시간이 차이나지 않고, 혹시나 나중에 다른 어플리케이션에서 로그를 쌓을 때 굳이 데이터 내부에 timestamp 를 만들어서 이용하기 보단 적재되는 시점을 기준으로 생각하는게 관리하기 편할 것으로 생각되어 이렇게 결정하게 되었다.
이렇게 함으로써 데이터가 적재되었고 대시보드를 아래처럼 만들게 되었다. Graylog 보다 훨씬 자유롭게 구성할 수 있었다.
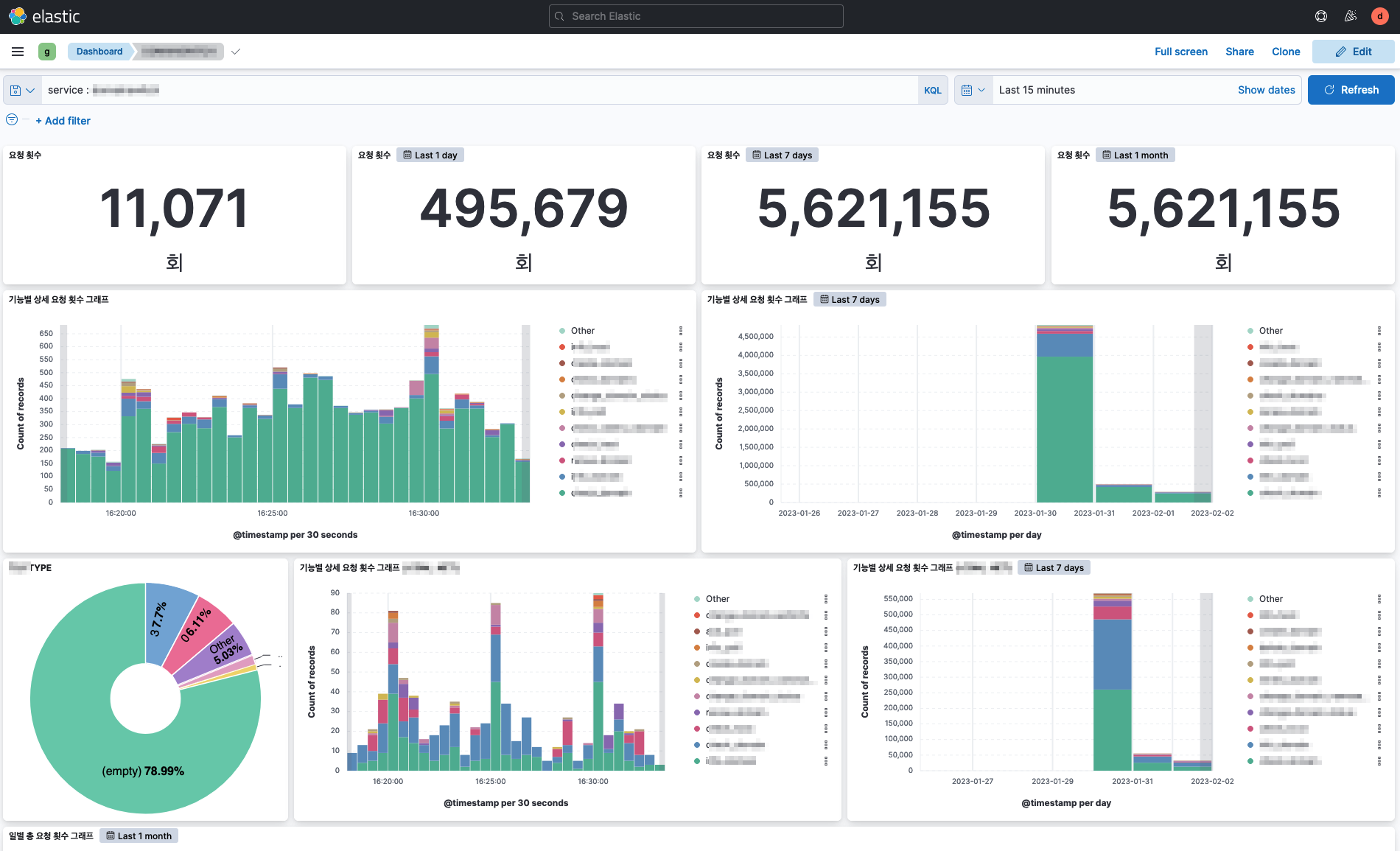
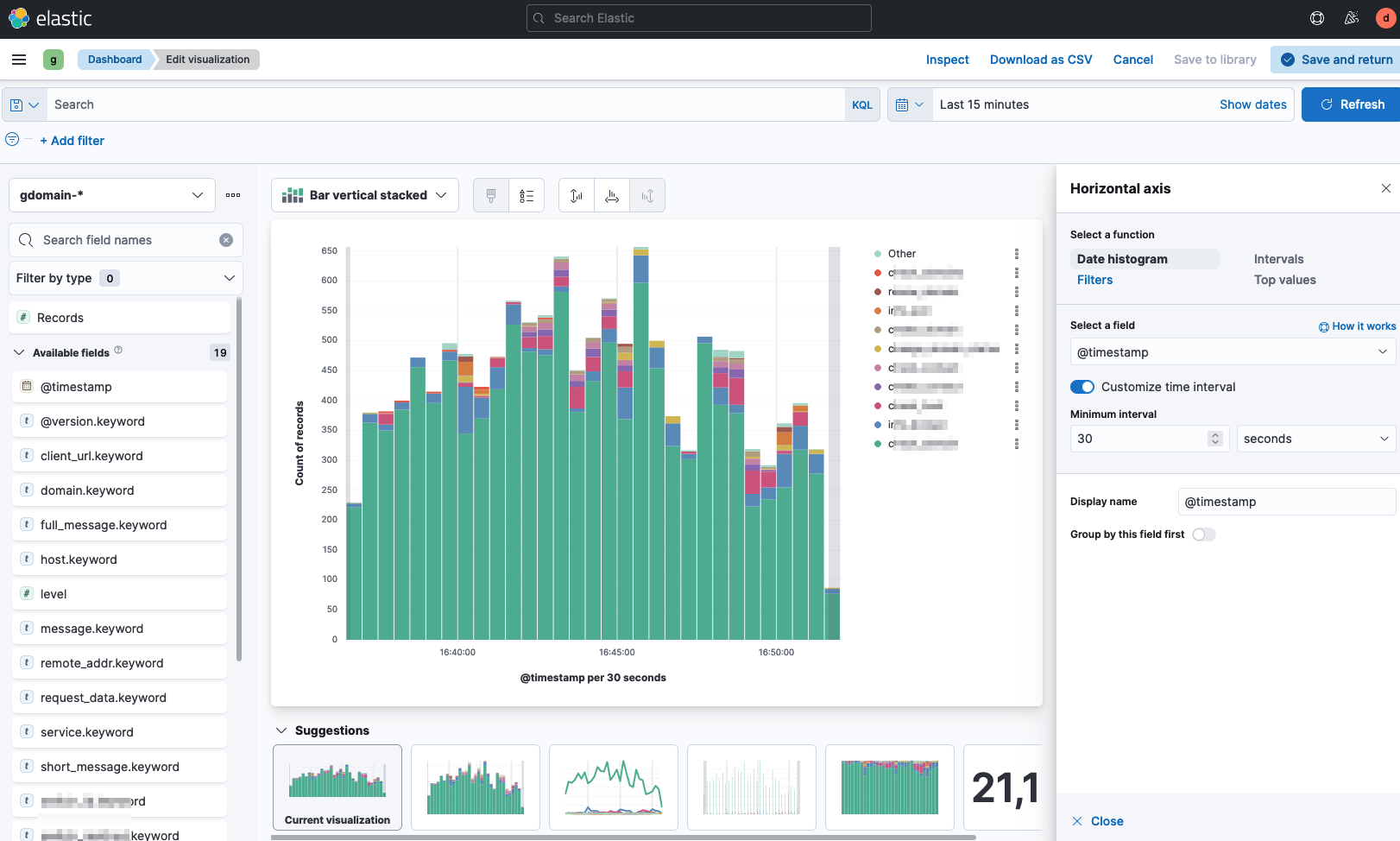
그래프를 표현할 때 아래의 'Customize time interval' 설정을 통해 간격을 자유롭게 설정할 수도 있다. Graylog 를 사용할 때 내가 정말 원했던 기능이었는데 쉽게 사용할 수 있었다.
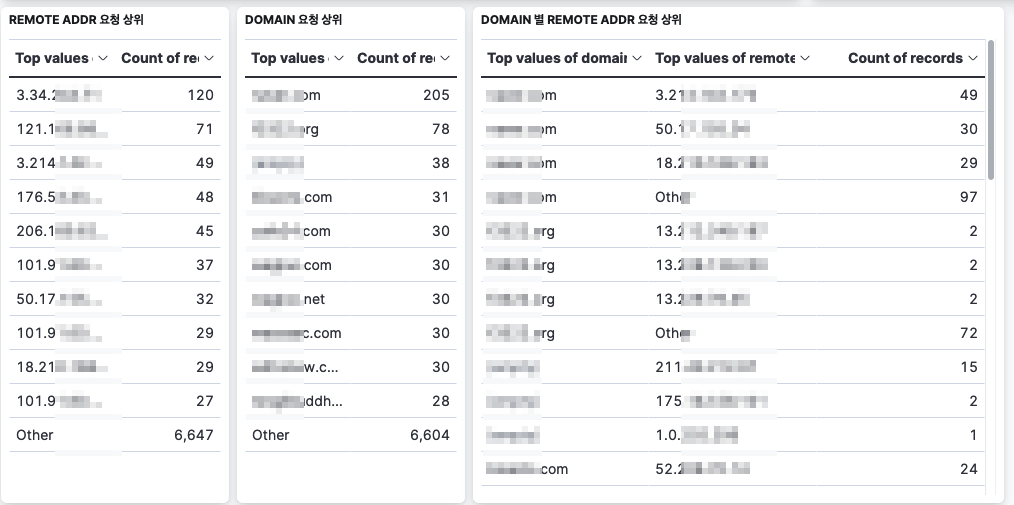
아래처럼 다른 데이터를 동시에 연관시켜서 설정할 수도 있었다. 테이블 뿐만 아니라 그래프 또한 마찬가지다.
Graylog 와 ELK 를 전부 사용해보면서 개인적으로는 ELK 로 사용하는 것이 logstash 나 대시보드 포함해서 자유롭게 구성할 수 있던 것이 마음에 들었다. Kibana 의 대시보드에서 시각화를 등록할 때 여러 방법들을 지원하고 있어서 나중에 어떤 데이터가 들어오느냐에 따라 어떻게 다르게 보여줄 수 있을지는 지속적으로 사용해가면서 알아가야겠다.
'회고' 카테고리의 다른 글
| [회고] 멀티모듈 고군분투 회고 (0) | 2024.03.13 |
|---|---|
| [회고] 2023년 (0) | 2024.01.01 |
| [회고] 2022년 (0) | 2023.01.01 |
| [회고] 2021년 (0) | 2022.03.27 |
| [회고] SVN에서 GIT으로 이전 후 코드 리뷰 도입을 돌이켜보며 (0) | 2022.03.27 |