
Oracle의 PIVOT 문법은 Oracle 11g부터 지원하는 기능으로 행을 열로 변환하여 사용할 수 있게 도와준다.
SELECT ( 출력컬럼 )
FROM ( PIVOT 대상 쿼리문 )
PIVOT ( 집계함수(집계컬럼) FOR 컬럼 IN (컬럼값 AS 별칭 ... )- FROM절에 대상이 되는 테이블의 모든 컬럼은 GROUP BY의 대상이 된다.
- PIVOT문에 가로로 출력할 컬럼은 가로로 나열할 때의 GROUP BY의 대상이 된다.
- 집계함수에 사용되는 컬럼은 집계 대상이므로 GROUP BY 대상에서 제외되고 나머지 컬럼들은 세로로 나열할 때 GROUP BY 대상이 된다.
예를 들면 EMP 테이블에 아래와 같은 데이터가 있다고 하자
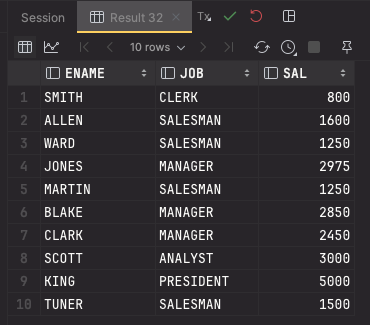
아래처럼 질의문을 작성하고
SELECT
*
FROM (
SELECT ENAME, JOB, SAL FROM EMP
)
PIVOT (
AVG(SAL) FOR JOB IN (
'ANALYST',
'CLERK',
'MANAGER',
'PRESIDENT',
'SALESMAN'
)
);실행해보면 아래와 같이 출력된다.
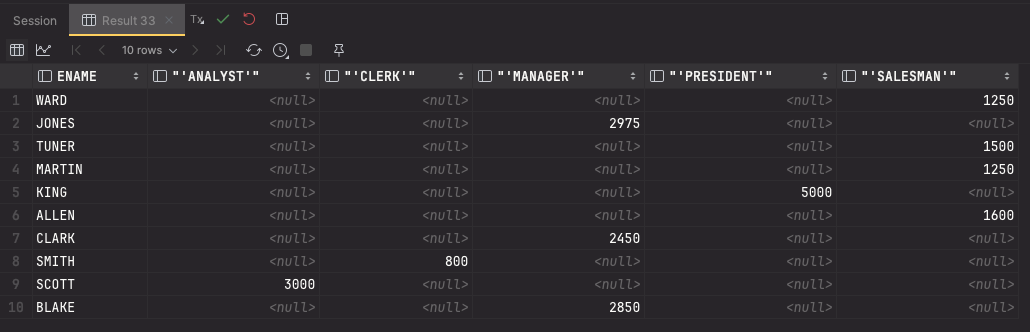
위를 통해
- ENAME 으로 GROUP BY 를 최초로 실행 (세로)
- JOB 으로 GROUP BY 를 실행 (가로)
- SAL 로 AVG 실행 (집계)
순으로 동작이 이루어진다고 생각하면 된다.
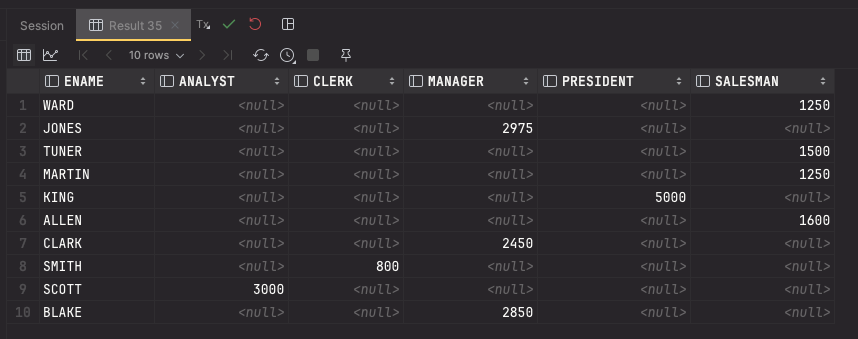
별칭을 줄 때는 아래처럼 AS 를 붙이면 된다.
SELECT
*
FROM (
SELECT ENAME, JOB, SAL FROM EMP
)
PIVOT (
AVG(SAL) FOR JOB IN (
'ANALYST' AS ANALYST,
'CLERK' AS CLERK,
'MANAGER' AS MANAGER,
'PRESIDENT' AS PRESIDENT,
'SALESMAN' AS SALESMAN
)
);
주의할 사항이 있는데 WHERE절에서 IN으로 서브쿼리를 통해 가져오려고 할 경우, 서브쿼리에서 작성된 조건에 따라 FULL SCAN이 발생할 수 있다.
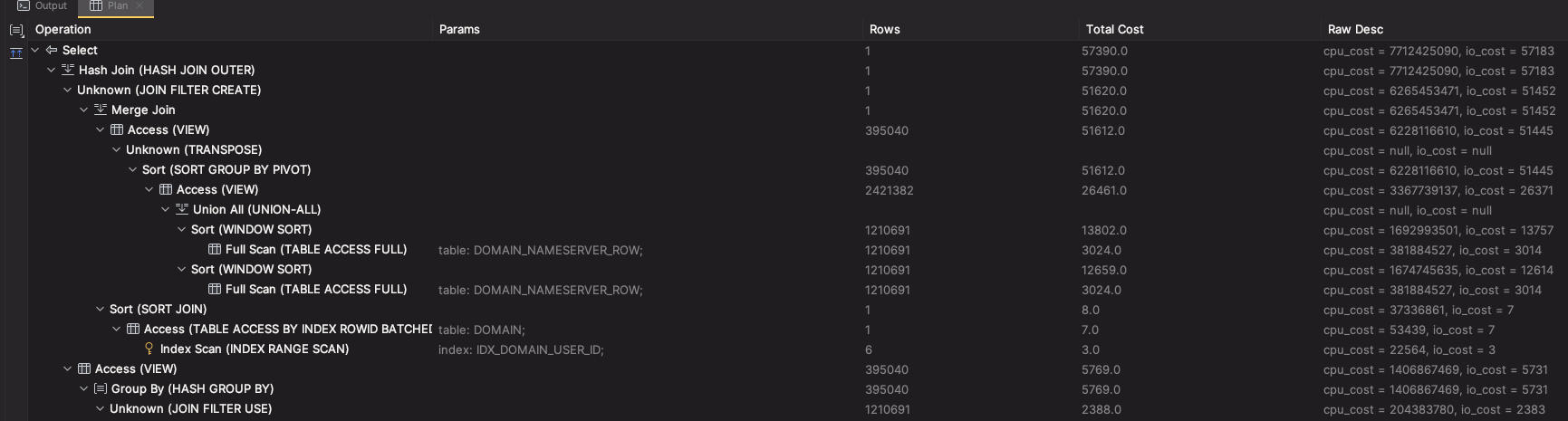
사내에서 100만개 이상의 데이터를 가지고 있는 네임서버 정보를 행으로 관리하고 있는데 이를 열로 변경해야 하는 경우가 있었고, 네임서버들의 인덱스는 도메인 테이블의 고유번호와 네임서버 이름으로 복합키로 관리되고 있었다.
SELECT
*
FROM
v_domain_nameserver_row
WHERE
domain_seqno IN (
SELECT
seqno
FROM
domain
WHERE
user_id = 'someuser'
AND status IN ('7', '8', '9')
);위 쿼리에서 v_domain_nameserver_row 는 domain_nameserver_row 라는 테이블을 피봇으로 쿼리를 작성하여 view로 만든 것이고 이를 외부에서 다시 조건을 거는 질의문이다.
서브쿼리에 인덱스가 포함되어 있지 않다 보니 아래처럼 FULL SCAN이 발생되었다.
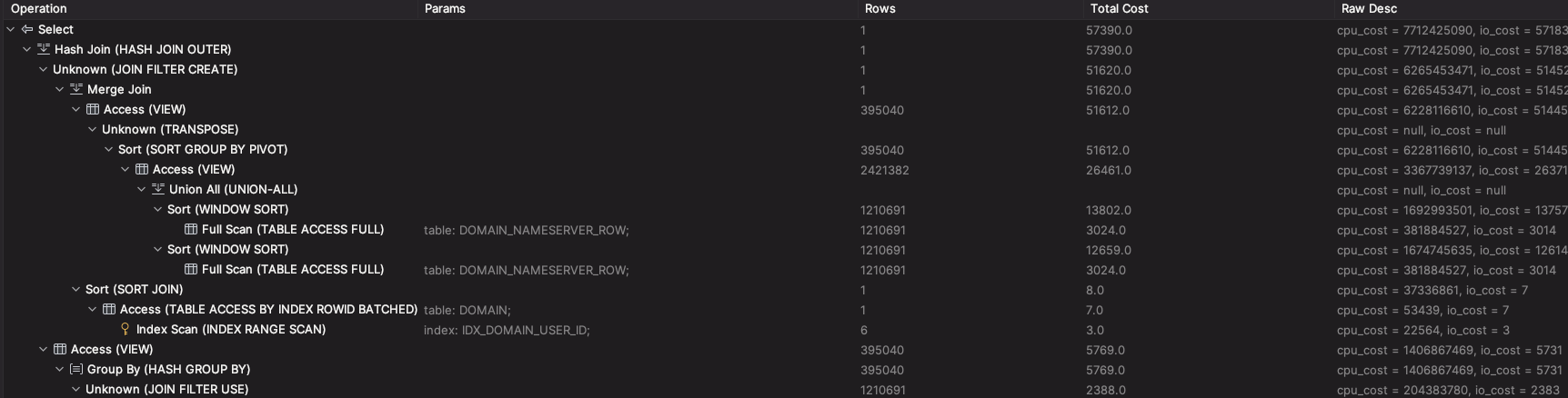
이렇게 단일 또는 여러 데이터를 조회할 때는 PIVOT을 사용하기 보다 직접 GROUP BY와 집계함수를 사용해서 이용하는 편이 좋을 수 있다.
SELECT
d.domain_seqno
, nameserver1, nameserverip1
, nameserver2, nameserverip2
, (SELECT
MAX(registdate)
FROM
domain_nameserver_row
WHERE domain_seqno = d.domain_seqno) AS updatedate
FROM (
SELECT domain_seqno, nameserver as value, 'nameserver' || ROW_NUMBER() OVER(PARTITION BY domain_seqno ORDER BY regstamp ASC) as fields_name
FROM domain_nameserver_row
UNION ALL
SELECT domain_seqno, nameserverip AS value, 'nameserverip' || ROW_NUMBER() OVER(PARTITION BY domain_seqno ORDER BY regstamp ASC) as fields_name
FROM domain_nameserver_row
) PIVOT (
LISTAGG(value, ',') WITHIN GROUP (ORDER BY value) FOR fields_name IN (
'nameserver1' AS nameserver1, 'nameserverip1' AS nameserverip1
, 'nameserver2' AS nameserver2, 'nameserverip2' AS nameserverip2
)
) d;위와 같은 쿼리를
SELECT
d.domain_seqno
, regexp_substr(d.nameserver, '[^,]+', 1, 1) as nameserver1
, regexp_substr(d.nameserverip, '[^,]+', 1, 1) as nameserverip1
, regexp_substr(d.nameserver, '[^,]+', 1, 2) as nameserver2
, regexp_substr(d.nameserverip, '[^,]+', 1, 2) as nameserverip2
, d.updatedate
FROM (
SELECT
ns.DOMAIN_SEQNO
, listagg(nameserver, ',') within group ( order by REGSTAMP asc ) as nameserver
, listagg(nameserverip, ',') within group ( order by REGSTAMP asc ) as nameserverip
, max(REGISTDATE) as updatedate
FROM domain_nameserver_row ns
GROUP BY ns.domain_seqno
) d위처럼 변경할 수 있다.
이 경우 전체 조회 시 쿼리 성능이 기하급수적으로 떨어지는 문제가 있지만 그 대신 조건으로 단일 또는 여러 개의 데이터를 지정해서 가져올 경우 문제없이 인덱스를 통해 가져올 수 있다.


'프로그래밍 > DB' 카테고리의 다른 글
| [DB] Oracle 날짜 계산 시 INTERVAL 보단 ADD_MONTHS 를 사용하자 (1) | 2024.03.04 |
|---|---|
| [DB] H2 데이터베이스 조회 시 한글 깨짐 수정 (0) | 2022.10.01 |
| [DB] H2 데이터베이스 설정 초기화 (0) | 2022.09.28 |
| [DB] Oracle 특정 값 max/min 에 대한 column 선택 (0) | 2022.06.08 |
| [DB] Can't connect to local MySQL server through socket '/tmp/mysql.sock' (0) | 2019.08.29 |